What Are Response Procedures?
Response procedures are predefined, role-based instructions that guide an organization through the management of abnormal situations, incidents, and emergencies. Unlike general operational guidance, response procedures are event-driven. They activate when something goes wrong, escalates, or deviates from normal operating conditions.
Their purpose is to ensure that incidents are handled consistently, proportionately, and without delay. By removing ambiguity during high-pressure situations, response procedures help personnel focus on assessment, decision-making, escalation, coordination, and closure rather than improvisation.
In professional environments such as control rooms, critical infrastructure, hospitality venues, construction sites, campuses, or public events, response procedures are a prerequisite for maintaining safety, operational continuity, and defensible governance.
What Is Incident Escalation in Response Procedures?
Incident escalation is the structured process of increasing attention, authority, coordination, or response capability when an incident exceeds routine handling thresholds. It is not simply the act of informing a supervisor. In mature operating models, escalation is a defined decision framework based on severity, impact, uncertainty, and the potential for further consequences.
Within response procedures, incident escalation determines when an issue remains at operational level, when it requires supervisory or specialist involvement, and when it must be elevated to senior leadership, crisis management, or external authorities. This makes escalation a core control mechanism rather than an administrative afterthought.
Well-designed response procedures define escalation triggers clearly. These may include life safety risk, service disruption, repeated occurrence, authority notification requirements, reputational exposure, or failure of initial controls. Without these thresholds, organizations tend to over-escalate minor issues and under-escalate serious events.
Why Structured Incident Escalation Matters
Incidents rarely fail because of missing technology. They fail because people are unsure who should act, when to escalate, or how far to go. Structured incident escalation closes this gap by defining clear triggers, authority levels, and coordination pathways.
Well-designed escalation within response procedures reduces response time, prevents unnecessary leadership involvement in low-level events, and ensures that serious incidents receive the right level of attention before consequences increase. It also protects organizations from operational, legal, and reputational risk by demonstrating due diligence and consistent governance.
Most importantly, structured incident escalation creates predictability. Everyone involved knows what happens next, even when the situation itself is unpredictable.
Incident Escalation Levels Explained
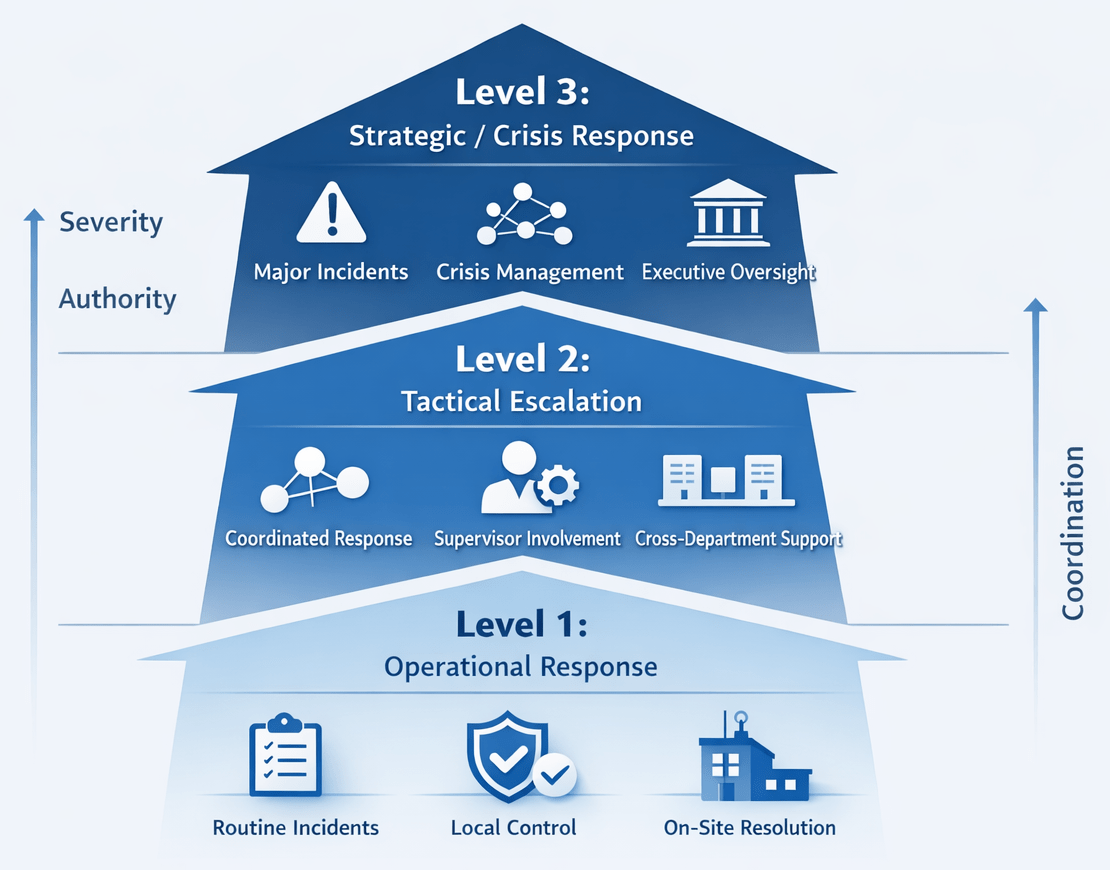
A structured incident escalation model helps organizations respond proportionately, consistently, and without delay. The purpose of escalation levels is not to make incidents appear more formal than they are, but to define when additional authority, coordination, specialist involvement, or crisis leadership is required.
In practice, escalation levels provide a shared operating language. They help control rooms, supervisors, and management distinguish between incidents that can be resolved operationally, incidents that require tactical coordination, and incidents that demand strategic leadership and external engagement.
Level 1 – Operational Response
Level 1 covers incidents and irregularities that can be managed by on-duty operational staff using existing resources, procedures, and authority. These events do not present an immediate threat to life, critical assets, or business continuity, and they can normally be resolved without supervisory escalation beyond standard reporting requirements.
Typical Level 1 incidents include minor safety observations, low-impact equipment faults, routine access control issues, minor traffic disruptions, or isolated alarms that can be verified and closed without wider consequence.
Typical Level 1 characteristics include:
- limited impact and low complexity
- clear ownership by operational staff
- no immediate need for cross-functional coordination
- resolution using normal shift resources
- documentation for reporting and trend analysis
Level 2 – Tactical Escalation
Level 2 is triggered when an incident exceeds routine handling capability, begins to escalate, or requires structured supervisory or specialist coordination. At this stage, the incident may still be controllable, but it is no longer appropriate to manage it only through normal operational resources.
Level 2 incidents may involve injuries, repeated alarms, service disruption, system impairment, elevated security risk, or events that require authority notification, specialist support, or coordinated action across multiple teams.
Typical Level 2 escalation triggers include:
- failure of initial controls or repeated occurrence
- cross-functional coordination requirements
- increasing operational or safety impact
- need for supervisory decision-making
- mandatory authority or stakeholder notification
At this level, communications become more structured, documentation becomes more important, and decision-making should follow defined escalation logic rather than informal judgement alone.
Level 3 – Strategic / Crisis Response
Level 3 represents major incidents or crises with actual or potential severe consequences. These incidents require senior leadership involvement, strategic decision-making, and often direct coordination with external authorities, emergency services, or crisis management structures.
At this level, priorities extend beyond immediate response. They include life safety, command and control, stakeholder communication, business continuity, legal and reputational implications, and recovery planning.
Typical Level 3 indicators include:
- serious life safety threat or multiple casualties
- major operational disruption or infrastructure failure
- widespread impact across multiple functions or sites
- high reputational, legal, or regulatory exposure
- activation of crisis management or external emergency command structures
Why Escalation Levels Matter
Escalation levels prevent two common failures in incident management: under-reaction and over-reaction. Without defined thresholds, minor issues can consume senior leadership attention, while serious incidents may remain under-managed until their impact increases.
A structured escalation model ensures proportionality. Each incident is handled at the lowest effective level, but with clear criteria for escalation when impact, uncertainty, or complexity increases.
This structure also supports accountability and consistency. Each escalation level defines authority, responsibilities, communication requirements, and documentation expectations, enabling effective training, post-incident review, and continuous improvement across control room operations.
Incident Escalation Workflow in Control Rooms
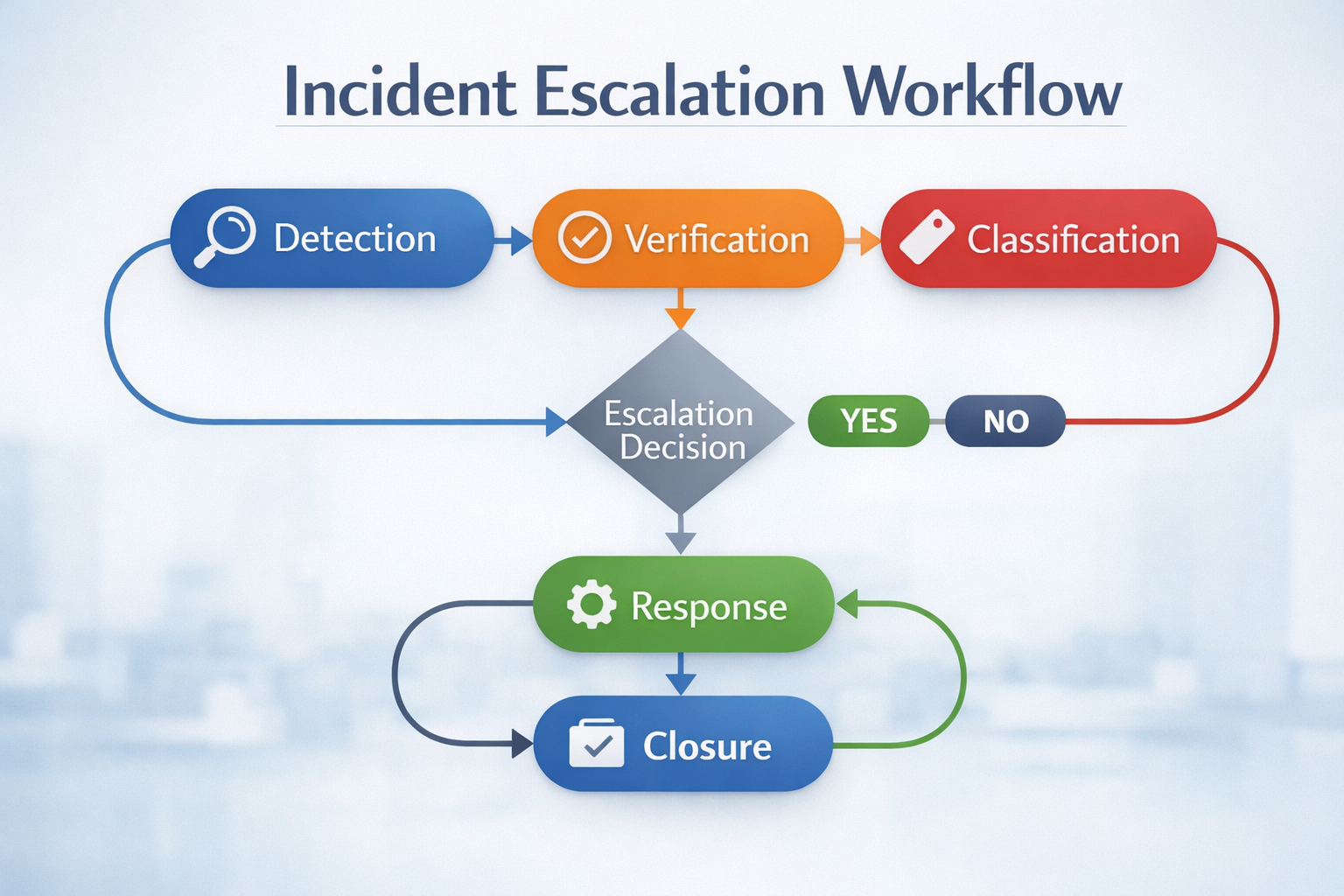
Incident escalation is most effective when it follows a defined workflow rather than relying on judgement alone. In control rooms and integrated operations environments, a structured workflow helps personnel move from detection to closure in a consistent, defensible, and time-critical manner.
Although workflows vary by environment, most response procedures follow the same core sequence: detect the event, verify the situation, classify the incident, determine the escalation level, coordinate the response, and close the incident with complete documentation. This structure reduces ambiguity and ensures that escalation decisions are based on defined criteria rather than informal habits.
Where integrated platforms are used, such as PSIM or command and control systems, the escalation workflow should be reflected in system configuration, but always derived from operational requirements rather than technology constraints.
In larger incidents, escalation may interface with formal command structures such as the Incident Command System (ICS), which defines roles, responsibilities, and coordination mechanisms across responding agencies.
Structured incident escalation and coordination principles align with established crisis management frameworks such as ISO 22320, which defines requirements for incident response, command, and control.
Typical Incident Escalation Workflow
- Detection: an alarm, report, observation, system alert, or authority notification indicates that something abnormal has occurred.
- Verification: the initial information is checked to confirm whether the event is valid, false, incomplete, or still developing.
- Classification: the event is assigned to the correct category and sub-category in the incident register.
- Escalation decision: the incident is assessed against defined thresholds to determine whether it remains operational, requires tactical coordination, or must be escalated to strategic or crisis level.
- Response and coordination: the required resources, communications, authority notifications, and control measures are activated.
- Closure and reporting: the incident is closed only when actions are complete, documentation is sufficient, and any follow-up requirements are assigned.
In mature control room environments, this workflow is supported by response procedures, escalation logic, and structured documentation requirements. Where integrated platforms or PSIM are used, the workflow should be reflected in system design, but the operational logic must be defined before the technology is configured.
A structured workflow also improves training and performance management. Personnel can be trained against repeatable decision points, and incident reviews can assess whether verification, escalation, coordination, and closure were completed correctly.
Response Procedures vs Standard Operating Procedures (SOPs)

A common misconception is that response procedures and standard operating procedures serve the same purpose. In practice, they support different operating conditions and different decision needs.
Standard operating procedures (SOPs) describe how routine activities are performed under normal conditions. They are designed to support consistency, efficiency, compliance, and repeatability during business-as-usual operations.
Response procedures, by contrast, are activated when normal conditions break down. They are specifically designed to manage undesired situations such as incidents, disruptions, safety events, or abnormal system behavior. Their purpose is not routine execution, but structured response, escalation, coordination, and control under time pressure.
The difference is operational. Standard operating procedures support day-to-day activities such as access control, patrol coordination, reporting, system monitoring, and routine communications. Response procedures address situations where something has gone wrong or is likely to escalate. They define how to assess the situation, apply escalation logic, coordinate response, and restore control.
In mature operating models, both are required. SOPs keep the control room functioning predictably from shift to shift, while response procedures provide the escalation logic and coordination pathways needed when events deviate from normal conditions. Organizations that rely on SOPs alone often discover that routine discipline does not automatically translate into effective incident handling.
For control rooms and integrated operations environments, the strongest approach is to align both document types under one operating model: SOPs for routine execution, and response procedures for abnormal events, escalation, and coordinated response.
In simple terms, SOPs keep operations running. Response procedures manage situations where operations are disrupted, degraded, or at risk. Both are essential, but they serve fundamentally different purposes within a control room operating model.
Incident Classification and Response Procedure Structure
Effective incident escalation depends on consistent classification. Without a structured incident model, escalation decisions become subjective, reporting becomes inconsistent, and performance analysis loses meaning.
In practice, response procedures should not be written for every individual event. This creates duplication, inconsistency, and unnecessary complexity. Instead, procedures should be defined at sub-category level, where incidents share similar characteristics, escalation logic, and response requirements.
This approach allows organizations to manage hundreds of event types through a structured and scalable framework. Each sub-category defines triggers, escalation thresholds, roles, coordination requirements, and closure criteria, while individual event types are mapped consistently within that structure.
In our framework, response procedures are organized into 11 standardized incident categories, covering 388 distinct event types. This ensures comprehensive coverage without overlap, while maintaining consistency across control room operations, reporting, and performance management.
The categories below illustrate how incidents are structured and grouped. Each category contains multiple sub-categories, and each sub-category is supported by a dedicated response procedure aligned to a consistent escalation model.
Effective incident escalation depends on consistent classification. Without a structured incident model, escalation decisions become subjective, reporting becomes inconsistent, and performance analysis becomes unreliable.
In this framework, response procedures are not defined for every individual event. Instead, they are structured at sub-category level, where incidents share similar characteristics, escalation logic, and response requirements. This avoids duplication and ensures consistency across operations.
The incident register currently includes over 350 distinct event types, organized into standardized categories and sub-categories. Each sub-category is supported by a dedicated response procedure, ensuring that escalation, coordination, and decision-making follow a consistent and repeatable model.
Alert / Alarm
- Fire & Life Safety Alarms
- Personal Safety
- Vertical Transportation (Lifts / Elevators)
- Security Alarms
- Environmental & HSE Threshold Alarms
- Technical / System Health Alarms
- Public Warning & Authority Alerts
Fire
- Confirmed Fire Incidents
- Smoke / Heat / Explosion Events
- Fire System Activation
- Hot Work & High-Risk Activities
Medical
- Medical Emergency
- Injury – Occupational
- Heat & Environmental Medical Conditions
- Illness & Non-Traumatic Conditions
- Medical Alerts & Calls
- Mass Casualty & Multiple Patients
- Medical Fatalities
Security
- Violent Crime Against Person
- Non-Violent Crime Against Person
- Crime Against Property
- Access & Perimeter Security Violations
- Suspicious Activity
- Vehicle-Related Security Incidents
- Public Order & Crowd-Related Incidents
- Threats & Intelligence
- Security System Abuse & Compromise
- Lost & Found – Persons
- Lost & Found – Property
Safety
- Unsafe Acts
- Unsafe Conditions
- Near Miss
- Safety Incident – Non-Injury
- Permit to Work (PTW) Violations
- High-Risk Activities
- Safety Equipment & Control Failures
- Safety Inspections & Compliance
Traffic
- Traffic Accidents & Collisions
- Traffic Violations & Unsafe Driving
- Traffic Congestion & Flow Disruption
- Road & Infrastructure Conditions
- Traffic Control & Access Management
- Vehicle Breakdown & Immobilization
- Weather-Related Traffic Events
- Parking Violations & Stoppages
Technical
- Power & Electrical Systems
- ICT & Network Services
- Control Room / PSIM Platform
- CCTV / VMS (Video Systems)
- Access Control Systems (ACS) and Identity Systems
- Intrusion Detection / Perimeter Detection Systems
- BMS / MEP Systems
- Fire & Life Safety Interfaces (Technical Only)
- Environmental Monitoring Systems (Technical Only)
- Critical Infrastructure and Specialized Systems
- Cybersecurity Events (Technical)
- Fire System Impairment & Degradation
Environmental
- Environmental Uncontrolled Releases
- Air Quality & Emissions
- Water & Marine Environment
- Waste Management & Materials Handling
- Noise & Vibration
Disaster
- Structural & Infrastructure Collapse
- Major Industrial & Technological Disasters
- Mass Casualty & Human Impact (Beyond Medical Emergency)
- Public Safety & Order Breakdown
Welfare
- Living & Accommodation Conditions
- Food, Water & Basic Needs
- Worker Well-Being & Fatigue
- Worker Relations & Grievances
- Mental & Psychosocial Welfare
- Workforce Support & Facilities
Planned
- Planned System Impairments
- Planned Inspections, Audits & Compliance
- Planned Drills, Exercises & Training
- Planned Visits & Engagements
- Planned High-Risk Activities
- Planned Traffic & Access Changes
This category-based approach enables scalable incident management, consistent escalation, and reliable reporting across hundreds of event types without introducing unnecessary complexity or duplication.
Response Procedures as an Indicator of Operational Maturity
The presence of structured response procedures and clearly defined incident escalation models is a strong indicator of operational maturity. Organizations that rely on informal escalation, individual judgement, or ad-hoc coordination expose themselves to unnecessary operational, safety, and reputational risk.
In contrast, mature control room environments define how incidents are detected, classified, escalated, and managed before they occur. They establish clear escalation thresholds, decision authority, communication requirements, and documentation standards. This ensures that response is consistent across shifts, teams, and scenarios, rather than dependent on individual experience.
Operational maturity is also visible in how well response procedures are integrated into training, exercises, and system workflows. Procedures that exist only as documents have limited value. Procedures that are embedded in daily operations, supported by escalation logic, and tested through realistic scenarios become a reliable decision framework.
In complex environments, this maturity enables organizations to manage hundreds of incident types through a consistent model, align control room operations with field response, and maintain defensible governance across safety, security, and operational domains.
Ultimately, response procedures are not documentation. They are operational control mechanisms that ensure incidents are handled predictably, proportionately, and in line with defined escalation principles.
Example Incident Escalation Procedure (Simplified)
The example below illustrates how a response procedure is structured at sub-category level, using a simplified version of a suspicious activity procedure. In practice, procedures include additional detail, roles, and interfaces, but the core escalation logic remains consistent.
Example: Security – Suspicious Activity
Triggering Events:
Observation, report, or system alert indicating suspicious behavior, including suspicious persons, vehicles, unattended objects, or potential surveillance activity.
Initial Actions – Detection and Verification:
- acknowledge and log the report in the control room
- identify location, type of activity, and reporting source
- review CCTV, access systems, or available data
- dispatch security for discreet observation if required
Assessment and Situational Awareness:
- establish a common operational picture across systems and teams
- identify behavior patterns, movement, and duration
- check for links to previous incidents or alerts
- assess potential risk to people, assets, or operations
Incident Classification and Escalation:
- Level 1: suspicious but benign activity, manageable locally
- Level 2: concerning or persistent suspicious behavior requiring coordinated response
- Level 3: credible hostile reconnaissance or threat indicator requiring immediate escalation
Response and Coordination:
- Level 1: monitor, document, and resolve locally where appropriate
- Level 2: increase surveillance, involve supervisors, and coordinate response teams
- Level 3: notify authorities, establish control measures, and support external response
Escalation and External Interface:
- escalation decisions are owned by the Duty Manager or designated authority
- external agencies are notified based on defined thresholds
- control room maintains coordination and information flow
Closure and Reporting:
- confirm resolution and safe conditions
- complete structured incident report
- preserve relevant data (CCTV, access logs, communications)
- identify follow-up actions and intelligence value
This simplified example reflects how response procedures structure incident escalation, decision-making, and coordination. In a full implementation, each sub-category procedure follows a similar model, aligned to escalation levels, operational roles, and system workflows.
Example: Medical Emergency (Simplified)
Triggering Events:
Report of injury, illness, collapse, or medical distress observed by staff, CCTV, or public.
Initial Actions – Detection and Verification:
- acknowledge and log the report
- confirm location and condition of the individual
- dispatch nearest trained responders or first aiders
- maintain communication with reporting party
Assessment and Escalation:
- Level 1: minor injury or illness, manageable on-site
- Level 2: serious condition requiring medical support or ambulance
- Level 3: life-threatening emergency requiring immediate emergency services and site-wide coordination
Response and Coordination:
- provide first aid within capability
- coordinate access for emergency services
- manage crowd and scene control if required
- support communication with authorities and management
Closure and Reporting:
- confirm patient transfer or resolution
- complete incident report
- record response time and actions taken